Fortran中文件批量操作方法
代码展示
1 | program main |
再fortran中,通过对一个字符串进行数据写入write(str2,”(I4.4)”)input,这样就可以将整型变量input转变成长度为4的字符串(1—->0001),通过这样的方式就可以通过循环来实现批量文献读写。
在这里,同时将input当作了打开文件的标示号,其实这里也可以只用确定的标示号来进行同样的操作。利用循环变量做标示号可能会遇到这个文件标示号你在这个循环中已经用过了,那么再次使用可能会报错或者将之前的文件内容修改。说这么多都是虚的,上代码演示一下。
1 | program main |
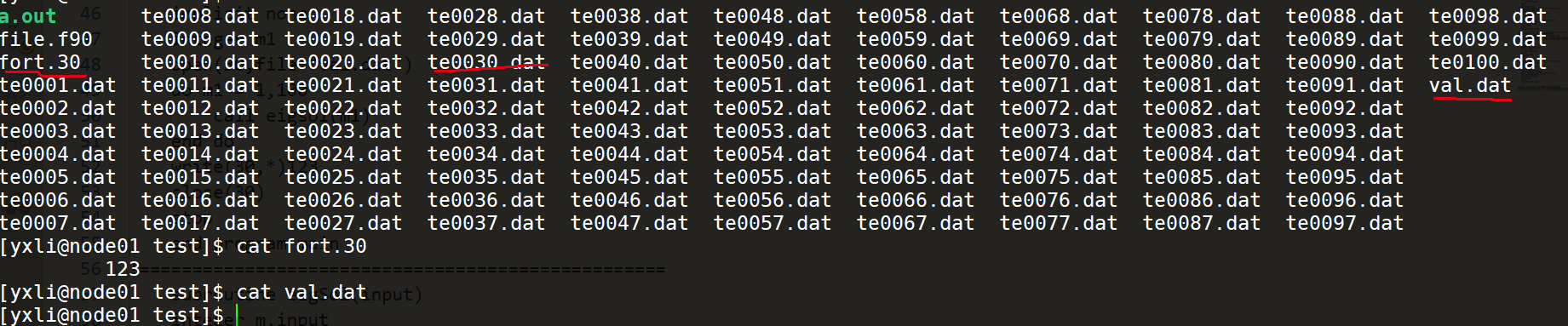
这里可以看到,因为在循环之前先打开了30这个文件,但是还没有向30中写入数据,之后就开始了循环操作,由于循环操作中会重新打开以此30号文件,完成读写后关闭,这个时候再执行write(30,*)123就会产生fort.30这个文件,它里面的内容是123,而val.dat中则什么都没有。
鉴于该网站分享的大都是学习笔记,作者水平有限,若发现有问题可以发邮件给我
- yxliphy@gmail.com
也非常欢迎喜欢分享的小伙伴投稿
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Yu-Xuan's Blog!

相关推荐
2019-01-01
p-wave 超导体Vortex中的Majorana zero mode
整理研究生接触的第一个科研工作。 研究生开始时,导师给的第一个任务就是重复一篇关于p-wave超导Vortex中Majorana零能模的文章。从刚开始一无所知的小白,到完整复现文章内容还是学...

2025-08-06
Fortran使用中笔记
将看到的Fortran中常用的一些语法记录起来,方便查阅。 Fortran中常用的库函数总结1. Cheevd 厄密矩阵本征值与本征矢的求解 2. getrf,getri getrf 对一...
2020-07-03
Hamiltonian构建时的基矢选择
看文献的时候,经常会遇到哈密顿量通常使用Pauli矩阵写出来,然后告诉你基矢的形式,但是每个人的习惯不同就会使的同一个哈密顿量可以有不同形式的写法,恰好这个问题也困扰我很久,所以正好借此将这个基...
评论
公告

欢迎关注公众号,有趣的内容也会在上面同步。 有密码的文章属于正在建设中或者没有通过验证的内容,若有需要可通过邮件联系。