1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
|
using LinearAlgebra,DelimitedFiles,Printf,MPI,Dates
function ham(kx::Float64,ky::Float64)
t0::Float64 = 0.1
t1x::Float64 = -0.483 * t0
t1z::Float64 = -0.110 * t0
t2x::Float64 = 0.069 * t0
t2z::Float64 = -0.017 * t0
t3xz::Float64 = 0.239 * t0
t4xz::Float64 = -0.034 * t0
tvx::Float64 = 0.005 * t0
tvz::Float64 = -0.635 * t0
ex::Float64 = 0.776 * t0
ez::Float64 = 0.409 * t0
ham = zeros(ComplexF64,4,4)
ham[1,1] = 2 * t1x * (cos(kx) + cos(ky)) + 4 * t2x*cos(kx)*cos(ky) + ex
ham[2,2] = 2 * t1z * (cos(kx) + cos(ky)) + 4 * t2z*cos(kx)*cos(ky) + ez
ham[1,2] = 2 * t3xz * (cos(kx) - cos(ky))
ham[2,1] = 2 * t3xz * (cos(kx) - cos(ky))
ham[3,3] = 2 * t1x * (cos(kx) + cos(ky)) + 4 * t2x*cos(kx)*cos(ky) + ex
ham[4,4] = 2 * t1z * (cos(kx) + cos(ky)) + 4 * t2z*cos(kx)*cos(ky) + ez
ham[3,4] = 2 * t3xz * (cos(kx) - cos(ky))
ham[4,3] = 2 * t3xz * (cos(kx) - cos(ky))
ham[1,3] = tvx
ham[1,4] = 2 * t4xz * (cos(kx) - cos(ky))
ham[2,3] = 2 * t4xz * (cos(kx) - cos(ky))
ham[2,4] = tvz
ham[3,1] = tvx
ham[4,1] = 2 * t4xz * (cos(kx) - cos(ky))
ham[3,2] = 2 * t4xz * (cos(kx) - cos(ky))
ham[4,2] = tvz
val,vec = eigen(ham)
return val,vec
end
function fsd(x::Float64)
T::Float64 = 0.001
return 1/(exp(x/T) + 1)
end
function chi0(qx::Float64,qy::Float64,omega::Float64,nk::Int64)
klist = range(-pi,pi,length = nk)
bearchi0 = zeros(ComplexF64,4,4)
for kx in klist
for ky in klist
val,vec = ham(kx,ky)
valq,vecq = ham(kx + qx,ky + qy)
for l1 in 1:4,l2 in 1:4
re1::ComplexF64 = 0
for m in 1:4,n in 1:4
re1 += (fsd(val[n]) - fsd(valq[m]))/(im * (omega + 0.0001) + val[n] - valq[m]) *
vecq[l1,m]' * vecq[l2,m] * vec[l2,n]' * vec[l1,n]
end
bearchi0[l1,l2] += re1
end
end
end
return -1/nk^2 * bearchi0
end
function chi(qx::Float64,qy::Float64,omega::Float64,nk::Int64)
U0::Float64 = 3.0
J0::Float64 = 0.4
a1 = diagm(ones(2))
a2 = zeros(Float64,2,2)
I0 = diagm(ones(4))
a2[1,1] = U0
a2[2,2] = U0
a2[1,2] = J0/2
a2[2,1] = J0/2
gamma = kron(a1,a2)
bearchi0 = chi0(qx,qy,omega,nk)
chitemp = inv(I0 - bearchi0 * gamma) * bearchi0
return imag(sum(chitemp)),real(sum(chitemp))
end
function main1(nk::Int64)
klist = range(0,pi,length = nk)
qxlist = zeros(Float64,nk^2)
qylist = zeros(Float64,nk^2)
chilist = zeros(Float64,nk^2,2)
MPI.Init()
comm = MPI.COMM_WORLD
root = 0
numcore = MPI.Comm_size(comm)
indcore = MPI.Comm_rank(comm)
nki = floor(indcore * nk/numcore) + 1
nkf = floor((indcore + 1) * nk/numcore)
if (MPI.Comm_rank(comm) == root)
println("开始计算极化率: ",Dates.now())
println("Number of nk : ",nk)
end
for iqx in nki:nkf
for iqy in 1:nk
i0 = Int((iqx - 1) * nk + iqy)
iqx = Int(iqx)
iqy = Int(iqy)
qxlist[i0] = klist[iqx]
qylist[i0] = klist[iqy]
chilist[i0,1],chilist[i0,2] = chi(klist[iqx],klist[iqy],0.0,nk)
end
end
MPI.Barrier(comm)
qxlist = MPI.Reduce(qxlist,MPI.SUM,root,comm)
qylist = MPI.Reduce(qylist,MPI.SUM,root,comm)
chilist = MPI.Reduce(chilist,MPI.SUM,root,comm)
if (MPI.Comm_rank(comm) == root)
println("结束计算极化率: ",Dates.now())
temp1 = (a->(@sprintf "%3.2f" a)).(nk)
fx1 ="mpi-chi-nk-" * temp1 * ".dat"
f1 = open(fx1,"w")
x0 = (a->(@sprintf "%5.3f" a)).(qxlist)
y0 = (a->(@sprintf "%5.3f" a)).(qylist)
z0 = (a->(@sprintf "%5.3f" a)).(chilist[:,1])
z1 = (a->(@sprintf "%5.3f" a)).(chilist[:,2])
writedlm(f1,[x0 y0 z0 z1],"\t")
close(f1)
end
end
main1(128)
|
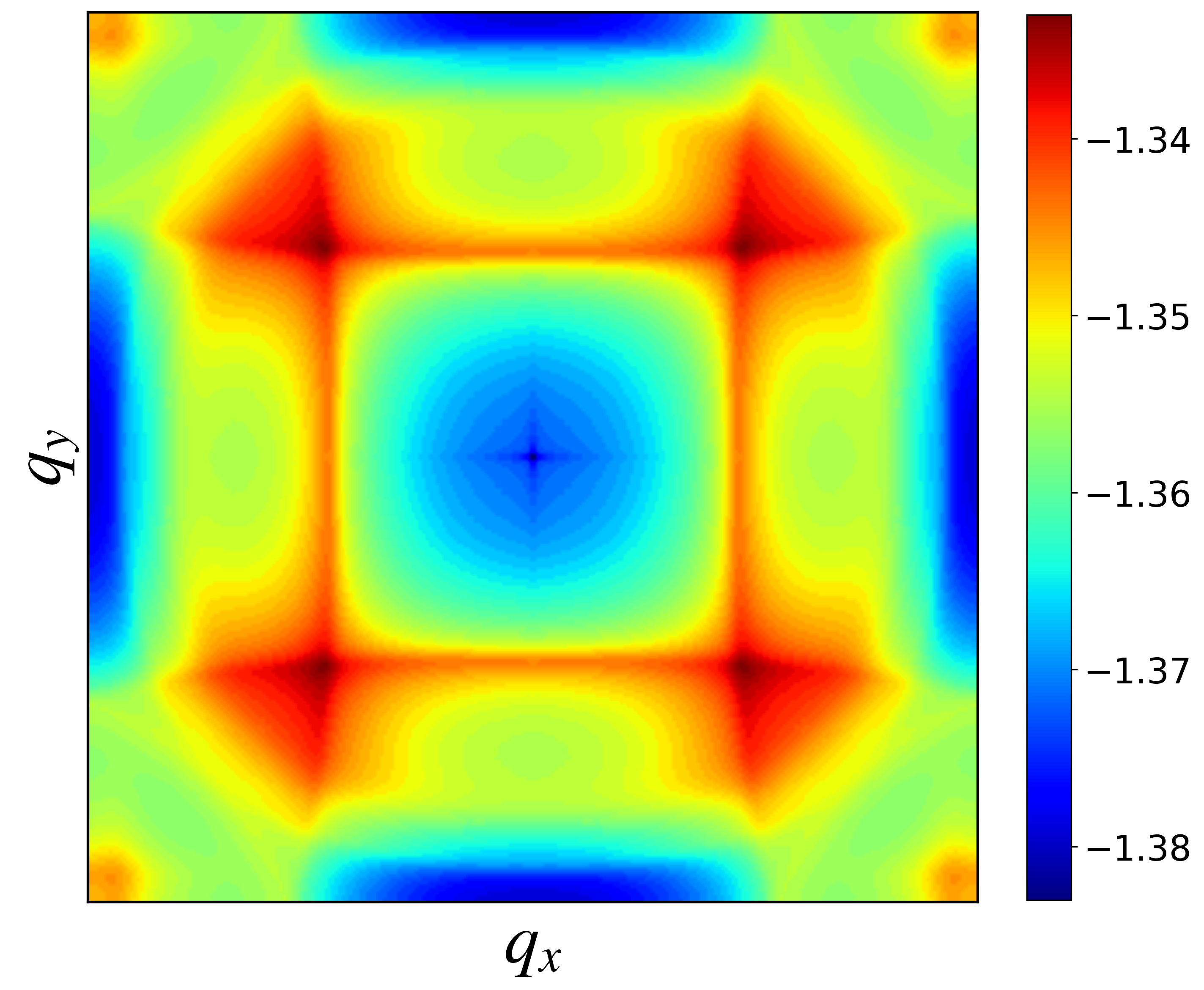 {:.border.rounded}{:width=”520px” height=”500px”}
{:.border.rounded}{:width=”520px” height=”500px”}
 wechat
wechat alipay
alipay