这里将Julia的并行实操了一下,并行计算了自旋极化率,在通常的计算中这部分的计算量是非常大的,而使用Julia的宏@distributed我目前无法实现跨节点计算,这里就尝试用MPI并行实现跨节点计算.
介绍
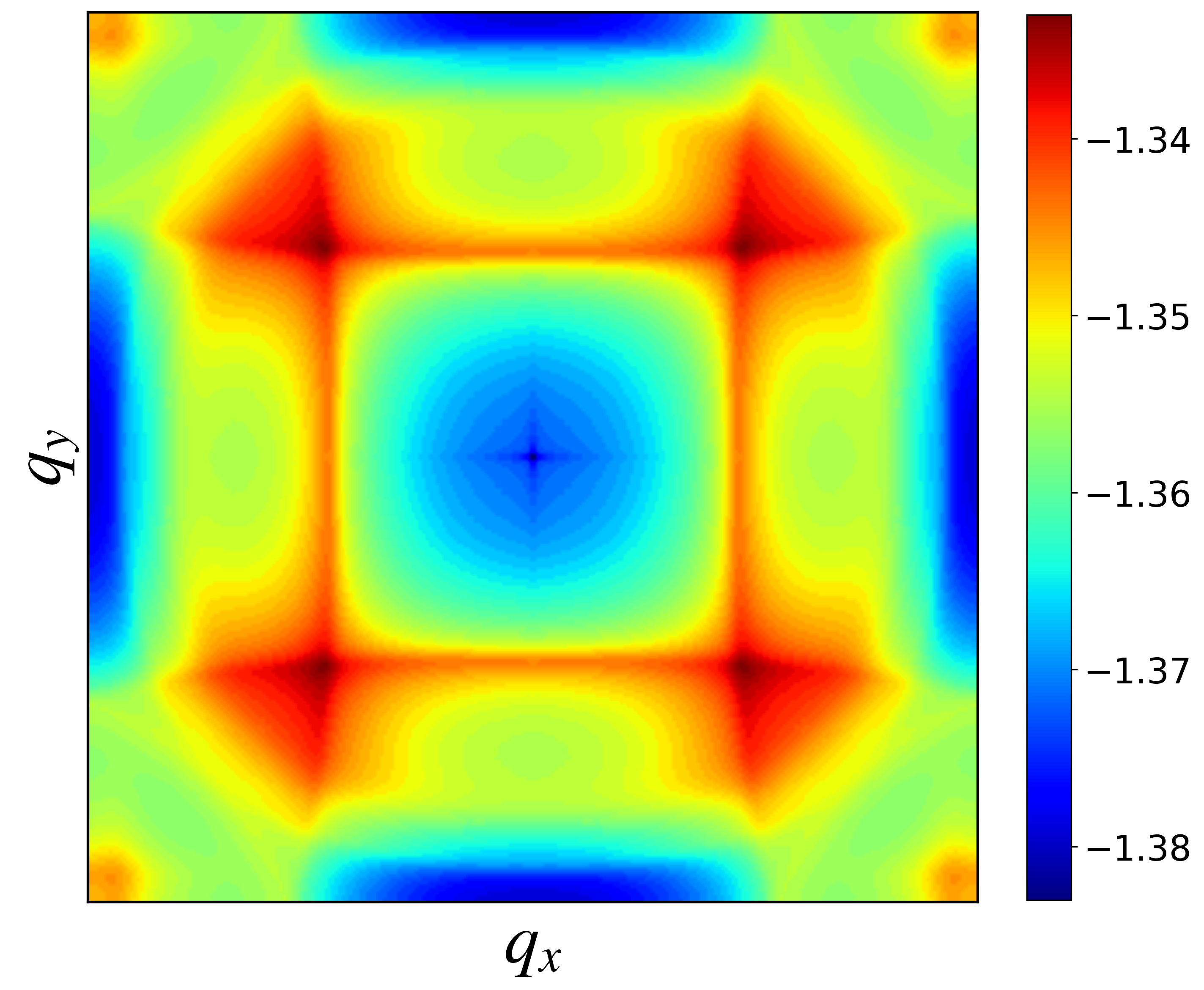
这里就不具体介绍自旋极化率是如何计算的了,直接上公式
\[\chi^{st}=-\frac{1}{2N}\sum_{\mathbf{k},mn}\frac{f(\epsilon^n(\mathbf{k}))-f(\epsilon^m(\mathbf{k}+\mathbf{q}))}{i\omega_n+\epsilon^n(\mathbf{k})-\epsilon^m(\mathbf{k}+\mathbf{q})}\langle m\rvert\mathbf{k}+\mathbf{q},t\rangle\langle \mathbf{k}+\mathbf{q},s\rvert m\rangle\langle s\rvert\mathbf{k},s\rangle\langle\mathbf{k},t\rvert n\rangle\]具体的内容可以参考Bilayer Two-Orbital Model of La$_3$Ni$_2$O$_7$ under Pressure这篇原文。
# 已经通过BBH模型检测
using LinearAlgebra,DelimitedFiles,Printf,MPI,Dates
#-------------------------------------------------------------------------------
function ham(kx::Float64,ky::Float64)
t0::Float64 = 0.1 # 缩放系数
t1x::Float64 = -0.483 * t0
t1z::Float64 = -0.110 * t0
t2x::Float64 = 0.069 * t0
t2z::Float64 = -0.017 * t0
t3xz::Float64 = 0.239 * t0
t4xz::Float64 = -0.034 * t0
tvx::Float64 = 0.005 * t0
tvz::Float64 = -0.635 * t0
ex::Float64 = 0.776 * t0
ez::Float64 = 0.409 * t0
ham = zeros(ComplexF64,4,4)
ham[1,1] = 2 * t1x * (cos(kx) + cos(ky)) + 4 * t2x*cos(kx)*cos(ky) + ex
ham[2,2] = 2 * t1z * (cos(kx) + cos(ky)) + 4 * t2z*cos(kx)*cos(ky) + ez
ham[1,2] = 2 * t3xz * (cos(kx) - cos(ky))
ham[2,1] = 2 * t3xz * (cos(kx) - cos(ky))
ham[3,3] = 2 * t1x * (cos(kx) + cos(ky)) + 4 * t2x*cos(kx)*cos(ky) + ex
ham[4,4] = 2 * t1z * (cos(kx) + cos(ky)) + 4 * t2z*cos(kx)*cos(ky) + ez
ham[3,4] = 2 * t3xz * (cos(kx) - cos(ky))
ham[4,3] = 2 * t3xz * (cos(kx) - cos(ky))
ham[1,3] = tvx
ham[1,4] = 2 * t4xz * (cos(kx) - cos(ky))
ham[2,3] = 2 * t4xz * (cos(kx) - cos(ky))
ham[2,4] = tvz
ham[3,1] = tvx
ham[4,1] = 2 * t4xz * (cos(kx) - cos(ky))
ham[3,2] = 2 * t4xz * (cos(kx) - cos(ky))
ham[4,2] = tvz
val,vec = eigen(ham)
return val,vec
end
#-------------------------------------------------------------------------------
function fsd(x::Float64)
T::Float64 = 0.001 # Temperature
return 1/(exp(x/T) + 1)
end
#-------------------------------------------------------------------------------
# 裸的自旋磁化率
function chi0(qx::Float64,qy::Float64,omega::Float64,nk::Int64)
# nk::Int64 = 100 # 点撒密一点才能找到费米面
klist = range(-pi,pi,length = nk)
bearchi0 = zeros(ComplexF64,4,4)
for kx in klist
for ky in klist
val,vec = ham(kx,ky)
valq,vecq = ham(kx + qx,ky + qy)
for l1 in 1:4,l2 in 1:4
re1::ComplexF64 = 0
for m in 1:4,n in 1:4
# 计算极化率
re1 += (fsd(val[n]) - fsd(valq[m]))/(im * (omega + 0.0001) + val[n] - valq[m]) *
vecq[l1,m]' * vecq[l2,m] * vec[l2,n]' * vec[l1,n]
# re1 += (fsd(val[n]) - fsd(valq[m]))/(im * (omega + 0.0001) + val[n] - valq[m]) *
# vecq[l1,m] * vecq[l2,m]' * vec[l2,n] * vec[l1,n]'
end
bearchi0[l1,l2] += re1
end
end
end
return -1/nk^2 * bearchi0
end
#-------------------------------------------------------------------------------
function chi(qx::Float64,qy::Float64,omega::Float64,nk::Int64)
U0::Float64 = 3.0
J0::Float64 = 0.4
a1 = diagm(ones(2))
a2 = zeros(Float64,2,2)
I0 = diagm(ones(4))
a2[1,1] = U0
a2[2,2] = U0
a2[1,2] = J0/2
a2[2,1] = J0/2
gamma = kron(a1,a2)
bearchi0 = chi0(qx,qy,omega,nk)
chitemp = inv(I0 - bearchi0 * gamma) * bearchi0
#return chitemp
return imag(sum(chitemp)),real(sum(chitemp))
end
#-------------------------------------------------------------------------------
function main1(nk::Int64)
# nk::Int64 = 200
klist = range(0,pi,length = nk)
qxlist = zeros(Float64,nk^2)
qylist = zeros(Float64,nk^2)
chilist = zeros(Float64,nk^2,2)
#*************************************************
# Parameter for MPI
MPI.Init()
comm = MPI.COMM_WORLD
root = 0
numcore = MPI.Comm_size(comm) # 申请的核心数量
indcore = MPI.Comm_rank(comm) # 核心的id标号
#*************************************************
#*************************************************
# 循环区间分配
nki = floor(indcore * nk/numcore) + 1
nkf = floor((indcore + 1) * nk/numcore)
if (MPI.Comm_rank(comm) == root)
println("开始计算极化率: ",Dates.now())
println("Number of nk : ",nk)
end
#*************************************************
for iqx in nki:nkf
# for iqx in 1:nk
for iqy in 1:nk
i0 = Int((iqx - 1) * nk + iqy)
iqx = Int(iqx)
iqy = Int(iqy)
qxlist[i0] = klist[iqx]
qylist[i0] = klist[iqy]
chilist[i0,1],chilist[i0,2] = chi(klist[iqx],klist[iqy],0.0,nk)
end
end
MPI.Barrier(comm)
qxlist = MPI.Reduce(qxlist,MPI.SUM,root,comm)
qylist = MPI.Reduce(qylist,MPI.SUM,root,comm)
chilist = MPI.Reduce(chilist,MPI.SUM,root,comm)
if (MPI.Comm_rank(comm) == root)
println("结束计算极化率: ",Dates.now())
temp1 = (a->(@sprintf "%3.2f" a)).(nk)
fx1 ="mpi-chi-nk-" * temp1 * ".dat"
f1 = open(fx1,"w")
x0 = (a->(@sprintf "%5.3f" a)).(qxlist)
y0 = (a->(@sprintf "%5.3f" a)).(qylist)
z0 = (a->(@sprintf "%5.3f" a)).(chilist[:,1])
z1 = (a->(@sprintf "%5.3f" a)).(chilist[:,2])
writedlm(f1,[x0 y0 z0 z1],"\t")
close(f1)
end
end
#-------------------------------------------------------------------------------
# @time hpath()
# @time ferminsurface(1000)
main1(128)
任务提交
集群上提交任务的脚本为
#!/bin/bash
#SBATCH --job-name=test
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=20
#SBATCH --cpus-per-task=1
#SBATCH -t 3-00:00:00
# load the environment
module purge
module load compiler/intel/2021.3.0
module load mpi/intelmpi/2021.3.0
module load apps/vasp/6.4.0-i21
module load apps/wannier90/3.1-i21
#your_home/soft/vasp6_d4/bin
# where is your binary file
source your_home/soft/anaconda/anaconda3/etc/profile.d/conda.sh
julia=your_home/soft/julia-1.9.4/bin/julia
python=your_home/soft/anaconda/anaconda3/bin/python3.11
NUM_MPI=$SLURM_NTASKS
echo "======== Job starts at `date +'%Y-%m-%d %T'` on `hostname` ======== "
mpirun -np ${NUM_MPI} julia file.jl
echo "======== Job ends at `date +'%Y-%m-%d %T'` on `hostname` ======== "
公众号
相关内容均会在公众号进行同步,若对该Blog感兴趣,欢迎关注微信公众号。

|
yxli406@gmail.com |