队列系统Torque安装
在进行第一性原理计算的时候,是需要用到队列系统去提交任务的,在这里就记录一下自己安装队列系统的过程 安装一般情况下Linux的软件都安装到/opt这个文件夹中,所以先在这里新建文件夹 cd /opt mkdir torque cd torque 首先你要确定自己有安装包,我这里的安装包是_Torque-6.1.2_,先将软件进行解压tar zxvf torque-6.1.2.tar.gz,接下来执行./configure --with-default-server=master,这里默认都是利用root进行的。这个设置完成后会提示提可以进行make,那么就执行make。如果没有安装包可执行 wget http://wpfilebase.s3.amazonaws.com/torque/torque-6.1.2.tar.gztar -zxvf torque-6.1.2.tar.gzcd torque-6.1.2/ 安装一些必要的依赖 yum install libxml2-devel openssl-devel gcc gcc-c++ boost-devel libtool-y 依赖安装完成后,进入到torque-6.1.2中执行 ./configure —prefix=/usr/local/torque —with-scp—with-default-server=mastermakemake installmake packages 这三个命令都需要执行一定的时间。接下来执行 libtool —finish /usr/local/torque/lib 服务配置cp contrib/init.d/{pbs_{server,sched,mom},trqauthd} /etc/init.d/for i in pbs_server pbs_sched pbs_mom trqauthd; do chkconfig —add $i; chkconfig $i on; done Torque环境变量设置TORQUE=/usr/local/torqueecho “TORQUE=$TORQUE” >> /etc/profileecho “export PATH=$PATH:$TORQUE/bin:$TORQUE/sbin”...
VASP编译安装
假期空闲,又不能外出学习交流,正好趁这段时间入门一下第一性原理计算,首先从安装VASP开始,这里记录一下自己的安装过程,说不定之后还会用的到。{:.success} intel fortran安装首先需要安装Intel Parallel studio XE2019,如果有教育邮箱,可以申请试用,有效期是一年,没有的话请自行解决,百度一堆教程。进入软件文件夹之后会看到一个install.sh的文件,执行命令./install.sh这里默认你已经拥有root权限。按照软件的提示一路往下走,之后就是要输入序列号了,如果是教育邮箱申请的,那么你的邮箱会收到这个序列号,我的是S477-LJST6J4M。之后的安装同样遵循默认选项,虽然可以自行选择哪些需要安装,哪些不需要安装,但因为这是新手初学,暂时先不关心这个问题。接下来就是一段时间的等待之后,就可以成功安装了。 安装结束之后,并不代表软件可以使用了,如果熟悉Linux系统的话,就知道我们需要设定一下环境变量,才能保证每次进入终端之后可以成功使用intel fortran。首先需要找到正确的安装路径,我的安装路径为 1/opt/intel 找到里面的这个文件 psxevars.sh对应的路径为 /opt/intel/parallel_studio_xe_2019打开.bashrc文件(注意前面有个英文句号,说明这是Linux中的隐藏文件),然后将环境变量加入 1source /opt/intel/parallel_studio_xe_2019/psxevars.sh 加入后保存.bashrc文件,然后执行source .bashrc这样就成功的将intel fortran安装到了机器上 检查intel fortran是否可以成功安装123icc -v ifort -v 这两个命令会分别返回c和fortran编译器的版本which ifort 这个命令则会返回ifort这个执行命令的路径,如果成功安装,则上面的命令都不会报错echo $MKLROOT 这个命令是告诉你你的mkl函数库在哪里,这个库函数主要是用来做矩阵运算的,一定要正确安装 编译intel...
Fortran中文件批量操作方法
Fortran属于比较古老的语言,自然不如现在大火的python等语言那么灵活,但是fortran的计算速度一直是其的优势,有时候再使用的过程中又会遇到要对不同的数据分开输出,这个时候就要利用Fortran的文件批量处理了,不过也是通过数据类型的转换,从而实现的。{:.success} 代码展示123456789101112131415161718192021 program main implicit none integer m1 do m1 = 1,100 call eigsol(m1) end do stop end program main!================================================== subroutine eigSol(input) integer m,input character*20::str1,str2,str3,str4 str1 = "file" str3 = ".dat" write(str2,"(I4.4)")input str4 = trim(str1)//trim(str2)//trim(str3) open(input,file=str4) write(input,*)input close(input) return end subroutine eigSol 再fortran中,通过对一个字符串进行数据写入write(str2,”(I4.4)”)input,这样就可以将整型变量input转变成长度为4的字符串(1—->0001),通过这样的方式就可以通过循环来实现批量文献读写。 在这里,同时将input当作了打开文件的标示号,其实这里也可以只用确定的标示号来进行同样的操作。利用循环变量做标示号可能会遇到这个文件标示号你在这个循环中已经用过了,那么再次使用可能会报错或者将之前的文件内容修改。说这么多都是虚的,上代码演示一下。 12345678910111213141516171819202122232425 program main implicit none ...
Mathematica群论工具GTPack安装及使用
最近准备仔细学习一遍群论,平时学习也喜欢结合计算机,这样对一些概念的理解可以更加透彻一些。恰好又找到了一本群论的书,且完全是利用Mathematica来对群论的概念进行讲解,正好在这里整理一下自己的学习笔记,可以随时作为参考。{:.info} GTPack安装这个安装包是这本书所使用的Group Theory in Solid State Physics and Photonics: Problem Solving with Mathematica,可以自行去寻找pdf。安装包是在它的官网上面下载,如果是新用户是需要注册后进行下载的。将安装包下载解压后里面会有GroupTheory的文件夹,如下图所示接下来说一下安装的问题,将安装包下载解压后里面会有GroupTheory的文件夹,我们需要将这个文件夹放到Mathematica的用户基础目录中的Applications这个文件夹中。这里不去说明什么叫用户基础目录,在MMA中运行$UserBaseDirectory[]就可以知道它的路径。比如我的基础目录为C:\\Users\\Administrator\\AppData\\Roaming\\Mathematica,下图就是我的用户基础目录中的一些文件夹,接下来只要将GroupTheory复制到Applications中即可。 GTPack使用通过上面的流程之后,其实在你每次打开Mathematica的时候,GTPack并不会被自动装载进来,不过也可以通过修改Mathematica的其实文件init.m去修改你每次打开Mathematica时软件需要自动进行的操作,可以设置让这个包自动装载进来。我们接下来是使用手动方式来加载。 只需要执行Needs[“GroupTheory`”]即可,这里仔细注意一下,GroupTheory后面有一个额外的符号,也就是笔记本电脑上数字键1左边的符号,记得是英文输入法状态下输入。如果是想用上面提及到的自动装载,那么把这句话加入到上面提到的init.m文件中即可。这里还有个问题没有解决,这个包是提供了参考帮助文档的,但是我还不懂怎么可以把这个增加到MMa内置的帮助文档中。{:.info} 公众号相关内容均会在公众号进行同步,若对该Blog感兴趣,欢迎关注微信公众号。{:.info} ...
Jupyter中安装Julia
Jupyter在数据科学方面用起来还是很方便,而且在里面可以同时运行多种变成语言,正好最近换了电脑需要重新安装julia,也就正好记录一下安装过程。{:.success}Jupyter是在Ananconda的组件,所以只要先下载安装Ananconda,那么自然就可以看到jupyter,且在安装过程中会自动安装好python,就不用再单独安装python了,而且此时的jupyter中是自带python的,接下来就是安装julia了。 julia在中文社区下载好之后,直接运行安装即可,这里记一下自己的安装目录,比如我的安装目录是D:\Julia-1.4.1,安装完成后就可以正常启动julia了,不过此时的julia只不过是一个基本的内容,还需要安装一系列的包。 在安装包之前要说明一下,我们在这里需要使用一下镜像网站来安装包,否则速度会非常慢,而且经常会失败,这里用到的是北京外国语的一个镜像,首先要找到你julia的startup.jl文件,这个文件的路径为D:\Julia-1.4.1\etc\julia\startup.jl也就是在安装目录下寻找,找到之后,刚开始这个文件中只有一些注释过的语句,我们需要在这个文件中加入 ENV[“JULIA_PKG_SERVER”] = “https://mirrors.bfsu.edu.cn/julia/static“ 加入之后,重启julia,然后查看版本信息即如图所示看到上图所示的信息之后就说明镜像设置成功了,接下就是安装将julia嵌入Jupyter的包IJulia了 import PkgPkg.add(“IJulia”)using IJulia 以此执行上面的三个命令之后,即可成功在Jupyter中安装Julia,接下来打开Jupyter进行新建文件是,就可以看到Julia的命令了 公众号相关内容均会在公众号进行同步,若对该Blog感兴趣,欢迎关注微信公众号。{:.info} Email yxliphy@gmail.com
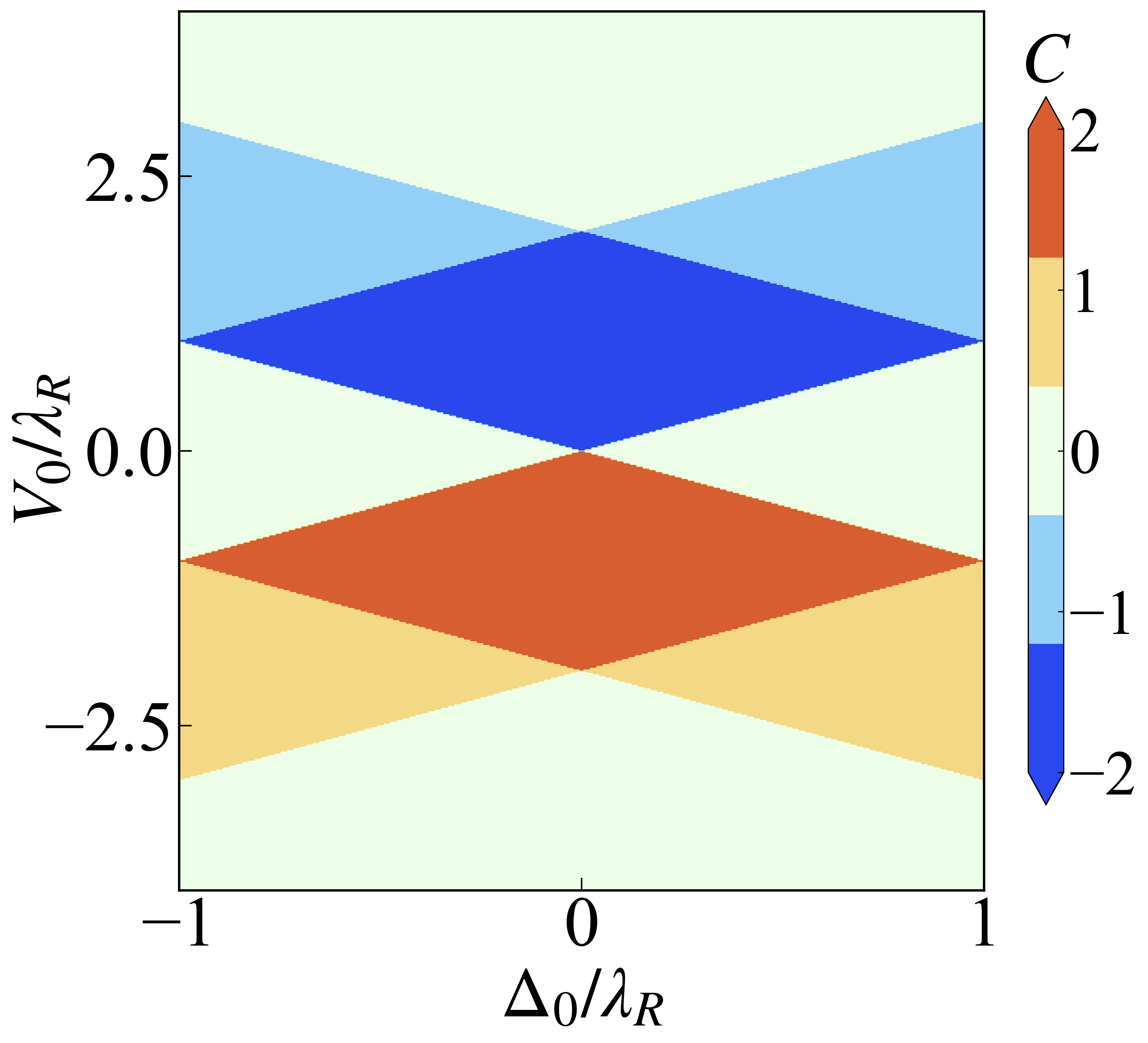
利用Green's function求态密度的两种方法
在这里先整理一个最简答的问题,再知道了体系的哈密顿量后,怎么求解系统的格林函数并求得态密度。{:.success} 数值角度考虑在这里以一个陈绝缘体的哈密顿量为例来演示具体每一步是如何进行的。 H(k_x,k_y)=t(\sin(k_x)s_x+\sin(k_y)s_y)+(1-\cos(k_x)-\cos(k_y))s_z这里的$s_i$代表Pauli矩阵,这是一个2*2的Hamiltonian,通常格林函数为$G(k_x,k_y,\omega)=\frac{1}{i\omega-\hat{H}}$,虽然这里在写法上是个分数的形式,但注意这里分母上的\hat{H}其实是个算符,这里请理解这一点,先不要将它就当作是这里的哈密顿量。接下来我们要计算格林函数,这里是要求倒数,那么对应到矩阵形式就是要求解$i\omega-H$这个矩阵的逆,这个时候就已经把算符$\hat{H}$写成具体的矩阵形式了,这个关系要捋清楚。 那么矩阵求逆就没什么好讲的了,对于这个2*2的矩阵解析和数值都是可以很轻松的求解出来。态密度的话就是把$k_x$和$k_y$对应下的格林函数积分即可 A(\omega)=\int_0^{2\pi} G(k_x,k_y,\omega)d\mathbf{k}下面附上Mathematica的代码作为示例,可以进行参考123456t=1.0;i=PauliMatrix[0];x=PauliMatrix[1];y=PauliMatrix[2];z=PauliMatrix[3];H[kx_,ky_]:=t(Sin[kx]x+Sin[ky]y)+(1-Cos[kx]-Cos[ky])z;G2[kx_,ky_,\[Omega]_]:=Inverse[\[Omega] i-H[kx,ky]]spec2[kx_,ky_,\[Omega]_]:=-Im@Tr@G2[kx,ky,\[Omega]]dos2[\[Omega]_]:=1/(2\[Pi])...